The Power of Large Language Models: Transforming Human-Machine Interaction
Large Language Models (LLMs) are foundational machine learning models that use deep learning algorithms to process and understand natural language. The term “large” in LLM refers to the scale of the model, both in terms of the amount of data it is trained on and the computational resources required for training
These models are trained on massive amounts of text data to learn patterns and entity relationships in the language. LLMs can perform many types of language tasks, such as translating languages, analyzing sentiments, chatbot conversations, and more.
They can understand complex textual data, identify entities and relationships between them, and generate new text that is coherent and grammatically accurate.By learning the patterns, structures, and nuances of language from these datasets, LLMs are capable of generating coherent and contextually relevant text in response to prompts or queries.
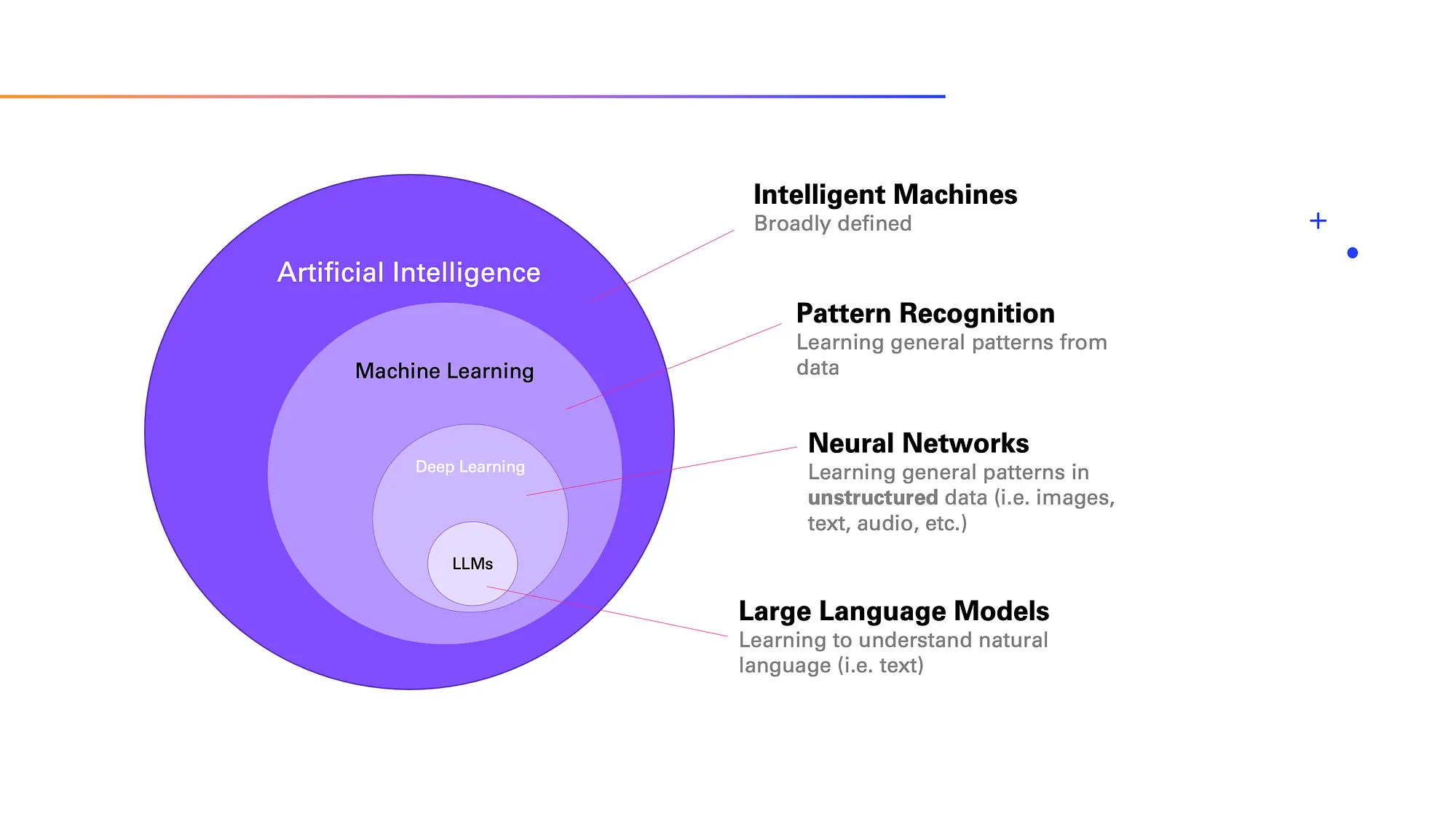
How do large language models work?
Large language models like GPT-3 (Generative Pre-trained Transformer 3) work based on a transformer architecture. Here’s a simplified explanation of how they Work:
- Learning from Lots of Text: These models start by reading a massive amount of text from the internet. It’s like learning from a giant library of information.
- Innovative Architecture: They use a unique structure called a transformer, which helps them understand and remember lots of information.
- Breaking Down Words: They look at sentences in smaller parts, like breaking words into pieces. This helps them work with language more efficiently.
- Understanding Words in Sentences: Unlike simple programs, these models understand individual words and how words relate to each other in a sentence. They get the whole picture.
- Getting Specialized: After the general learning, they can be trained more on specific topics to get good at certain things, like answering questions or writing about particular subjects.
- Doing Tasks: When you give them a prompt (a question or instruction), they use what they’ve learned to respond. It’s like having an intelligent assistant that can understand and generate text.
Difference Between Large Language Models and Generative AI:
Generative AI is like a big playground with lots of different toys for making new things. It can create poems, music, pictures, even invent new stuff!
Large Language Models are like the best word builders in that playground. They’re really good at using words to make stories, translate languages, answer questions, and even write code!
So, generative AI is the whole playground, and LLMs are the language experts in that playground.
Architecture of LLM:
The architecture of a large language model (LLM) typically revolves around transformer architectures, a class of deep learning models specifically designed for sequence transduction tasks, such as natural language processing (NLP). Here’s a brief overview:
The power of the transformer model lies in the ingenious self-attention mechanism. This mechanism contributes to accelerated learning compared to traditional models such as long short-term memory models. Self-attention empowers the transformer model with the remarkable capability to meticulously scrutinize distinct segments of a given sequence or even encompass the entire contextual essence of a sentence. This profound contextual awareness enables the model to make predictions with an elevated degree of accuracy and relevance.
Moreover, the transformer model architecture has several essential elements, each contributing to its robust performance:
- Input Embeddings: Words are transformed into high-dimensional vectors called embeddings. In large models, these embeddings can have very high dimensions, often ranging from 128 to 1024 dimensions or more.
- Positional Encodings: To account for the sequential nature of language, positional encodings are added to the input embeddings. These encodings provide information about the positions of words in a sequence.
- Multi-Head Self-Attention: Large models employ multiple parallel self-attention “heads,” each capturing different types of relationships and dependencies. This enhances the model’s ability to understand context across various scales.
- Layer Normalization and Residual Connections: As the data progresses through each sub-layer—a composition of self-attention and feedforward stages—layer normalization is strategically applied, fostering stable training. The introduction of residual connections serves to perpetuate and channel information from prior stages, effectively alleviating issues stemming from vanishing gradients.
- Feedforward Neural Networks: Following the traversal through self-attention layers, the model employs feedforward neural networks characterized by multiple layers and nonlinear activation functions. This stage facilitates the processing and transformation of the acquired representations, imprinted with the intricacies highlighted by the attention mechanisms.
What are the advantages of large language models?
LLMs present several advantages like:
- Accuracy – LLMs, in general, can provide highly accurate outputs for a range of questions and requests. They do present several challenges and limitations, however, as described in the below section.
- Broad range of applications – LLMs can enable innovations across fields, including advertising and marketing, e-commerce, education, finance, healthcare, human resources, and legal.
- Continuous improvement – By design, LLMs become more accurate and can expand in use cases as they are trained and used more frequently.
- Ease of training – It is relatively easy to train and fine-tune an LLM, assuming an organization has the available resources.
- Extensibility – Extensible systems empower organizations to adapt and evolve their applications based on current needs. LLMs make it easier for developers to update applications with new features and functionality.
- Fast learning – LLMs can quickly learn from input data and gradually improve their results with use.
- Flexibility – A single LLM can be applied for different tasks or use cases across an organization.
- Performance – LLMs can typically respond to prompts very quickly.
What are the challenges and limitations of large language models?
Despite the clear advantages of LLMs, all should consider several challenges and limitations of it:
- Bias – LLMs are only as good as the data they are trained on. LLMs can mirror the biases of the content on which they are trained.
- Consent – There is an ongoing debate about the ethicality of how LLMs are trained and, specifically, how systems are trained on data without a user’s consent and can replicate art, designs, or concepts that are copyrighted.
- Development and operational cost – It costs millions of dollars to build and maintain a private LLM, which is why most teams rely on LLMs offered by companies like Google and OpenAI.
- Glitch tokens – Since 2022, there has been a rise of prompts designed to cause LLMs to malfunction, a concept known as glitch tokens.
- Hallucination – Hallucination refers to the fact that LLMs can generate content that is not factually correct. This is caused when LLMs are trained on imperfect data or lack the fine-tuning to correctly understand the context of information it is pulling from.
- Greenhouse gas emissions – LLMs consume a significant amount of power to train and maintain (including data storage), which has a large environmental impact.
- Security – Organizations should not provide free LLMs with sensitive or confidential data or information, as everything the LLM receives will train its future outputs.
Examples of Large Language Model:
- GPT-3: The full form for GPT is a Generative pre-trained Transformer and this is the third version of such a model hence it is numbered as 3. This is developed by Open AI and you must have heard about Chat GPT which is launched by Open AI and is nothing but the GPT-3 model.
- ROBERTa– The full form for this is the Robustly Optimized BERT Pretraining Approach. In the series of attempts to improve the performance of the transformer architecture, RoBERTa is an enhanced version of the BERT model which is developed by Facebook AI Research.
- Google BERT (Bidirectional Encoder Representations from Transformers) – Google’s BERT is an open source model that is widely used for NLP. It is one of the earliest LLMs and has been adopted by both research and industry users.
- Google Gemini – Gemini is Google DeepMind’s family of proprietary multimodal LLMs, released in late December 2023. It was created to outperform OpenAI’s GPT models.
- Google PaLM (Pathway Language Model) – PaLM is a proprietary model created by Google. PaLM provides code generation, NLP, natural language generation, translation, and question-answering capabilities.
- Meta LLaMA (Large Language Model Meta AI) – Meta’s LLaMA is a family of autoregressive LLMs. LLaMA 2, released in partnership with Microsoft, is open-source and free for research and commercial use.
- OpenAI GPT (Generative Pre-Trained Transformer) – OpenAI’s GPT family of models were one of the first to introduce the transformer architecture. GPT is a generative language model used for a wide range of NLP applications. Newer GPT models are proprietary, however, versions like GPT-2 have been open sourced and made available to users for free.
- XLNet – XLNet is a pre-training method for NLP built by Carnegie Mellon University and Google to improve NLP tasks.